1. 主从复制
1.1 环境搭建
🎯启动命令
//启动服务器
redis-server redis.windows.conf
//启动客户端
redis-cli -h ip -p 端口
//查看当前redis实例的角色信息
info replication🎯主从复制的配置方式
首先
# 主节点配置自己绑定的ip
bind [master_ip]方法 1:命令行动态配置(推荐)
# 在从节点上执行
REPLICAOF [master_ip] [master_port]
# 或旧版本命令(Redis 小于 5.0)
SLAVEOF [master_ip] [master_port]方法 2:配置文件静态配置
replicaof [master_ip] [master_port]
# 如果主节点有密码
masterauth yourpassword🎯主从复制的关键配置项
| 配置项 | 说明 |
|---|---|
replicaof ip port | 指定主节点地址 |
masterauth password | 主节点密码(如果设置了 requirepass) |
replica-read-only yes | 从节点是否只读(默认 yes) |
repl-ping-replica-period 10 | 主节点每 10 秒 ping 一次从节点 |
repl-timeout 60 | 复制超时时间 |
repl-backlog-size 1mb | 复制积压缓冲区大小 |
repl-backlog-ttl 3600 | 如果长时间没有从节点,清空 backlog 的时间 |
1.2 主从复制
🎯概念
主从复制 是 Redis 提供的一种数据冗余机制,其中一个 Redis 实例作为 主节点(Master),一个或多个实例作为 从节点(Slave/Replica)。从节点会异步地复制主节点的所有写操作,保持数据的一致性。
🎯目标
| 目标 | 说明 |
|---|---|
| 数据冗余 | 多个副本避免单点故障 |
| 读写分离 | 主节点负责写,从节点分担读请求,提升并发能力 |
| 高可用基础 | 哨兵或集群依赖主从结构进行故障转移 |
| 备份支持 | 可在从节点上执行 BGSAVE,避免影响主节点性能 |
🎯主从复制的基本架构
+------------------+
| Client |
+--------+---------+
|
| 写请求
+--------v---------+ 复制流(异步)
| Master Node | -------------------+
+--------+---------+ |
| |
| 读请求 v
+--------v---------+ +---------+----------+
| Replica Node 1 | | Replica Node 2 |
+------------------+ +--------------------+- 所有写操作必须在 Master 上执行。
- 读操作可以分发到任意 Replica 节点(需客户端或代理支持)。
- Replica 节点默认是只读的(可通过 replica-read-only yes/no 配置)。
🎯主从复制的工作流程
主从复制分为两个阶段:
- 全量同步
- 增量同步
阶段一:全量同步(初次建立连接时)
当一个从节点第一次连接主节点,或者无法进行增量同步时,就会触发全量同步。步骤如下:
- 主节点接收 REPLCONF 或 SLAVEOF [master_ip] [port] 命令
- 从节点发起连接并发送 PSYNC ? -1,命令包括了主库的runID和复制进度offset,第一次不知道主库的runID,发送runID为?,offset为-1表示第一次复制
- 主节点执行 BGSAVE 生成 RDB 快照,将当前内存数据保存为 RDB 文件,将 RDB 文件通过网络发送给从节点,也将主节点的runID和复制进度offset给从库
- 持续将 BGSAVE 期间的新写命令缓存到复制缓冲区(replication buffer),将复制缓冲区中的增量命令发送给从节点
- 同步完成,进入“命令传播”阶段,开始增量同步

阶段二:增量同步(命令传播)
全量同步完成后,进入增量同步阶段,也叫“命令传播”。
- 主节点每执行一个写命令,就会将该命令异步发送给所有已连接的从节点。
- 从节点接收命令并立即执行,保持与主节点的数据一致。
1. 客户端发送 SET name "Tom" 到主节点
↓
2. 主节点执行命令,更新内存数据
↓
3. 主节点将该命令写入:
├──→ 复制积压缓冲区(replication backlog) 全局记录
└──→ 每个从节点的复制缓冲区(replication buffer) 点对点发送
↓
4. 主节点的 I/O 线程异步从各个 replication buffer 中读取数据,通过网络发送给对应的从节点
↓
5. 从节点接收命令并执行
↓
6. 从节点返回 ACK(可选,用于监控复制偏移量)🎯断线重连
- 从节点断线 → 其 replication buffer 被释放。
- 重连时发送 PSYNC [offset]。
- 主节点检查 offset 是否在 backlog 中:
- 是 → 从 backlog 读取数据,继续同步(部分重同步)。
- 否 → 必须全量同步。
为什么断线重连不能继续使用复制缓冲区?
每个从节点连接主节点时,主节点为其分配一个独立的输出缓冲区(即 replication buffer)。这个缓冲区是为该从节点服务的,用于存储发往该从节点的命令。当从节点断开连接后,它的复制缓冲区会被释放,因为主节点不再需要维护与该从节点的连接状态。
PSYNC 命令:支持断点续传的复制协议
Redis 2.8 引入了 PSYNC 命令,取代旧的 SYNC,支持部分重同步(Partial Resynchronization),避免每次断线都全量同步。
PSYNC [runid] [offset]- runid:主节点的唯一运行 ID(可通过 INFO server 查看 run_id)
- offset:从节点当前复制到的字节偏移量
两种响应:
| 响应 | 含义 |
|---|---|
FULLRESYNC [runid] [offset] | 需要全量同步(如 offset 不在缓冲区中) |
CONTINUE | 可以继续增量同步(从指定 offset 继续) |
条件:只有当主节点的复制积压缓冲区(repl_backlog_buffer)中还保留着从节点缺失的数据时,才能进行部分同步。
复制积压缓冲区(Replication Backlog)
这是一个环形缓冲区(circular buffer),由主节点维护,用于支持部分重同步。
- 默认大小:1MB(可通过 repl-backlog-size 配置)
- 记录最近传播的写命令
- 所有从节点共享同一个 backlog
如果网络闪断 1 秒,从节点只丢了少量命令,且这些命令还在 backlog 中 → 触发 CONTINUE,只同步缺失部分
如果断开时间太长,backlog 被覆盖 → 触发 FULLRESYNC,重新全量同步
🎯如何监控复制状态
使用 INFO replication 命令查看主从复制信息:
# 在主节点执行
redis-cli INFO replication输出示例:
role:master
connected_slaves:2
master_repl_offset:13000
slave0:ip=192.168.1.2,port=6379,state=online,offset=12345,lag=1
slave1:ip=192.168.1.3,port=6379,state=online,offset=12340,lag=2- offset:从节点复制偏移量
- lag:从节点与主节点的延迟(秒)
🎯主从网络中断怎么办
当主从库断连后,主库会把断连期间的写命令,写入replication buffer,同时也会把这些操作命令写入repl_backlog_buffer这个缓冲区,repl_backlog_buffer是一个环形缓冲区,主库会记录自己写到的位置,从库会记录自己已经读到的位置。
断连恢复后,从库会给主库发送同步命令,发送当前的slave_repl_offset给主库,主库会判断master_repl_offset和slave_repl_offset之间的差距,把这之间的命令同步给从库即可。
repl_backlog_buffer是一个环形缓冲区,所以写满之后,主库会继续写入,就会覆盖掉之前的写入操作,如果从库的读取速度比较慢,就会导致主从库之间数据不一致,可以调整repl_backlog_size的大小,一般就是缓存空间大小 = (主库写入速度*操作大小 - 主从库间网络传输命令速度*操作大小) * 2,也可以不是2倍。
另一方面,可以考虑切片集群来分担主库的请求压力。
🎯读写分离
Redis 本身不会自动做读写分离。即使你有从节点,只要客户端只连主节点,所有读请求仍由主节点处理。真正的读写分离必须由客户端或代理层显式实现,将读请求路由到从节点。
如果一个写请求发送到了从节点会怎么样?
默认行为:replica-read-only yes(推荐且默认配置),从节点拒绝所有写命令,并返回错误给客户端:
READONLY You can't write against a read only replica.特殊情况:replica-read-only no,从节点允许接收写命令,并在本地执行。主节点不知道这个 SET,它的数据仍然是旧的。其他从节点的数据也保持不变。
1.3 主-从-从模式
🎯概念
主-从-从(Master → Replica → Replica) 模式,这种结构也被称为 级联复制(Cascading Replication) 或 树状复制拓扑(Tree Replication Topology),它在某些场景下非常有用。
Master(主)
↓
Replica 1(一级从)
↓
Replica 2(二级从)Replica 1 直接复制主节点的数据。
Replica 2 不直接连接主节点,而是复制 Replica 1 的数据。
也就是说:从节点也可以作为其他从节点的“主节点”。
Redis 原生支持这种结构,称为 Slave of Slave(从的从)。
🎯如何配置主-从-从
步骤 1:启动三个 Redis 实例,主节点:6379,一级从节点(Replica 1):6380,二级从节点(Replica 2):6381
步骤 2:配置一级从节点(6380),此时,6380 成为 6379 的从节点。
redis-cli -p 6380
> REPLICAOF 127.0.0.1 6379步骤 3:配置二级从节点(6381),此时,6381 成为 6380 的从节点,形成 主 → 从 → 从 的链式结构。
redis-cli -p 6381
> REPLICAOF 127.0.0.1 6380🎯场景
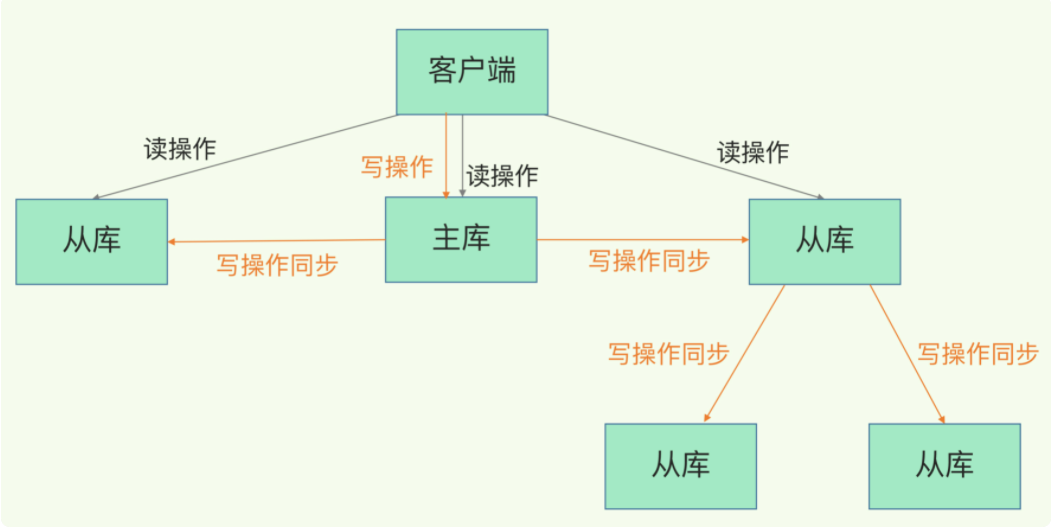
- 减轻主节点的网络和连接压力,如果主节点需要支持 上百个从节点,每个从节点都要建立连接、同步数据,会严重消耗主节点的 CPU、内存和网络带宽。使用级联结构,可以让 一级从节点分担复制压力,主节点只需同步少数几个一级从节点。
- 跨地域复制优化,主节点在 北京,一级从节点在 上海,多个二级从节点在 上海本地。北京到上海的链路只传输一次数据。上海内部通过高速内网同步,延迟低、带宽大。
- 主节点:核心业务,高安全。一级从节点:用于备份和分析。二级从节点:用于报表、缓存、只读查询。