1. Redis高性能总结
- 基于内存操作;
- 高性能的数据结构,例如哈希表,大部分简单的value查询时间复杂度是O(1);
- 采用单线程,避免了不必要的上下文切换和资源竞争;
- 采用非阻塞IO,IO多路复用机制。
2. Redis网络框架
Redis使用的是多路复用的IO网络模型。在redis只运行单线程的情况下,该机制可以同时存在多个监听套接字,一旦有请求到达就会交给redis线程处理,这就实现了redis线程处理多个IO流的效果。
Redis 的单线程指 Redis 的网络 IO 和键值对读写由一个线程来完成的,例如异步删除,Redis还是需要其他线程来完成的。
2.1 Redis 6.0 之前的网络模型:单线程事件循环
使用 I/O 多路复用(epoll / kqueue / select) 监听客户端连接和读写事件,类似一个单 Reactor 模型,所有操作串行执行,无并发、无锁竞争。
+---------------------+
| Event Loop 主线程 |
+----------+----------+
|
v
+------------------+
| I/O 多路复用器 | ← epoll_wait() / kevent()
| (epoll/kqueue) |
+------------------+
|
v
+------------------+ +------------------+
| 客户端连接事件 | | 客户端读事件 |
| accept() 新连接 | | read() 命令请求 |
+------------------+ +------------------+
| |
v v
+------------------+ +------------------+
| 添加到事件监听 | | 解析命令 → 执行命令 |
| (read event) | | (GET/SET/...) |
+------------------+ +------------------+
|
v
+------------------+
| write() 返回结果 |
+------------------+读取命令 → 解析 → 执行 → 写回响应,全部在主线程同步完成。
while (1) {
events = epoll_wait();
for (event : events) {
if (event.fd == listen_fd) {
accept(); // 接受新连接
} else if (event.mask & EPOLLIN) {
readQueryFromClient(); // 读取命令
} else if (event.mask & EPOLLOUT) {
sendReplyToClient(); // 发送响应
}
}
}2.2 Redis 6.0 的改进:多线程网络 I/O
解耦 网络 I/O 和 命令执行,让 I/O 操作可以并行,提升吞吐量,类似一个Reactor 多线程模型。
+------------------+
| 主线程 (Main) |
+------------------+
|
| 分发读事件
v
+--------------------------------------------------+
| I/O 线程池 (IO_THREADS_NUM) |
| [Thread-1] [Thread-2] [Thread-3] [Thread-4] |
| | | | | |
| v v v v |
| read() read() read() read() |
| 请求数据 请求数据 请求数据 请求数据 |
+--------------------------------------------------+
|
| 数据读完,通知主线程
v
+------------------+
| 主线程执行命令 |
| (GET/SET/...) |
+------------------+
|
| 分发写事件
v
+--------------------------------------------------+
| I/O 线程池 (IO_THREADS_NUM) |
| [Thread-1] [Thread-2] [Thread-3] [Thread-4] |
| | | | | |
| v v v v |
| write() write() write() write() |
| 返回结果 返回结果 返回结果 返回结果 |
+--------------------------------------------------+
|
v
+------------------+
| 主线程清理连接 |
+------------------+3. 数据结构和数据类型
3.1 redis基本操作
- redis默认有16个数据库,类似数组下标,从0开始,默认使用的就是下标0的数据库,可以通过以下命令选择数据库。
//选择下标1的数据库
select 1
//清空当前数据库
flushdb- 查看当前库所有的key
keys *- 判断是否存在key
exists key- 查看key的类型
type key- 删除key
//直接删除
del key
//异步删除key
unlink key- 给key设置过期时间
//给key设置60秒过期
expire key 60- 查看key还有多少过期时间,当返回值大于0,表示还有多少秒过期;当返回值为-1,表示永不过期;当返回值为-2,表示已经过期
ttl key3.2 五大基础数据类型
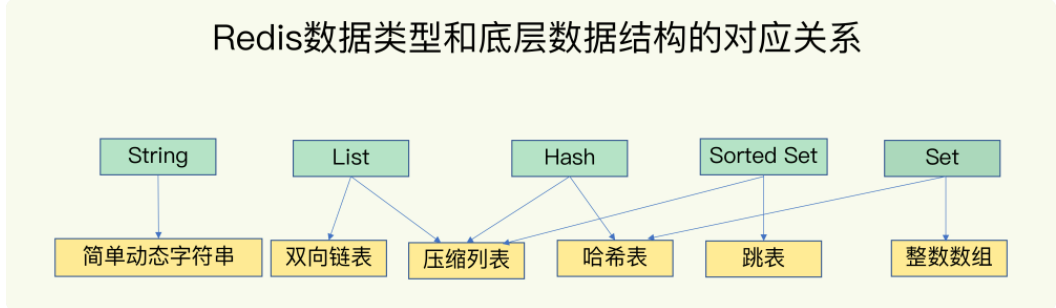
🎯String(字符串)
String是Redis中最基本的数据类型,一个key对应一个value,数据结构为简单的动态字符串,是可以修改的字符串。
//设置单个
set key value
//批量设置多个
mset key1 value1 key2 value2
// 当不存在key才设置,设置成功返回1,设置不成功返回0
// NX:是 "Not eXists" 的缩写
setnx key value
//仅当key不存在时才可添加,原子操作,一个失败,其他的都失败
msetnx key1 value1 key2 value2
//添加数据的同时设置过期时间
// ex:EXpiration
setex key second value
//获取值的同时替换新值
getset key value//获取单个
get key
//获取多个
mget key1 key2append key//自增1,increment
incr key
//自减1,decrement
decr key
//增长n
incrby key n
//减少n
decrby key n🎯List(列表)
Redis 的 List 类型是一种有序的、“一键多值”的数据结构,适用于存储一系列按插入顺序排列的字符串元素。它支持从列表的两端高效地执行插入和删除操作,同时也支持通过索引访问列表中的特定位置元素,但在大数据量时,通过索引访问中间节点的性能较差。
Redis 根据列表中元素的数量和大小,动态选择两种不同的底层实现方式:
- ziplist(压缩列表)
- 当列表中的元素较少且每个元素较小时使用。
- 特点是内存紧凑,所有元素连续存储在一个块内,提供了高效的内存利用率和小规模数据下的快速读写能力。
- 当列表元素数量超过
list-max-ziplist-entries(默认 512)或单个元素长度超过list-max-ziplist-value(默认 64 字节)时,Redis 会自动将 ziplist 转换为双向链表。
- linkedlist(双向链表)
- 适用于元素较多或单个元素较大的情况。
- 每个节点包含指向前后节点的指针,提供灵活的两端操作(如
LPUSH、RPUSH、LPOP、RPOP),但内存开销相对较大。 - 对于大规模数据集,虽然通过索引访问中间节点的性能较差,但两端操作依然高效。
//从左边插入
lpush key value1 value2 value3
//从右边插入
rpush key value1 value2 value3
//在目标值的前面或者后面插入一个值
linsert key before|after "目标值" "插入值"
//从左边开始,替换指定下标值
lset key index 替换值//从左边弹出一个值,当所有值弹出这个key就不存在了
lpop key
//从右边弹出一个值,当所有值弹出这个key就不存在了
rpop key
//从key1右边取一个值放入key2左边
rpoplpush key1 key2
//从左边开始删除n个目标值
lrem key 个数 目标值//从左边开始获取list坐标范围内的值,0到-1表示获取所有值
lrange key 起始坐标 结束坐标
//通过下标获取值
lindex key index
//获取列表长度
llen key🎯Set(集合)
Redis 的 Set 是一个无序、自动去重的集合数据结构,支持高效的集合运算(如 SADD、SISMEMBER、SINTER、SUNION 等),与 List 的功能和语义完全不同。
Set 的底层实现根据数据特征动态选择两种编码:
- intset(整数集合):当所有元素均为整数,且元素个数 ≤
set-max-intset-entries(默认 512)时使用。intset 是一种紧凑的、有序的整数集合,内存效率高。 - hashtable(哈希表):当元素包含非整数,或整数个数超过阈值时,Redis 会将底层结构升级为哈希表,每个元素作为哈希表的 key,value 为 NULL。
Redis 是一个内存数据库,内存就是成本。因此,Redis 的很多数据结构都采用了“小对象优化”策略 —— 当数据量小、类型简单时,用更紧凑的结构节省内存;当数据变大或变复杂时,再升级到通用但稍耗内存的结构。
sadd key value1 value2//从集合中获取所有元素,不删除
smembers key
//从集合中随机获取n个元素
srandmember key n
//判断是否存在value
sismember key value
//查找key中元素个数
scard key//从集合中删除value元素
srem key value
//随机从集合中删除一个元素,当集合中的元素都被吐出,集合就不存在了
spop key//将元素从集合key1移动到集合key2
smove key1 key2 value//求交集
sinter key1 key2
//求并集
sunion key1 key2
//求差集
sdiff key1 key2🎯Zset(有序集合)
ZSet(Sorted Set,有序集合)是 Redis 中最强大的数据结构之一,它结合了 集合(Set)的唯一性 和 字典序排序能力,同时引入了 分数(score) 作为排序依据,根据分数从小到大对成员进行排序,支持范围查询、排名计算等高级功能。
Redis 的 ZSet 之所以能同时实现高效的排序查询与快速的成员访问,其核心在于采用了 “双结构组合” 的精巧设计:在数据量较小且成员较短时,使用紧凑的 ziplist 节省内存;当数据增长超出阈值后,自动升级为由 跳跃表(skiplist)和哈希表(hashtable)共同支撑的复合结构 —— 其中 跳跃表按分值有序组织成员,支持 O(log N) 的范围查询与排名运算,而 哈希表则以成员(member)为键、分值(score)为值,实现 O(1) 的快速查找与存在性判断。这种“时间与空间兼顾、小数据与大数据分治”的设计,使得 ZSet 在保证强大功能的同时,依然具备出色的性能与内存利用率
zadd key score value score1 value1
//将集合中的某个元素分数+n
zincrby key n value//查询下标范围内的值
zrange key 起始下标 结束下标
//查询下标范围内的值携带分数
zrange key 起始下标 结束下标 withscores
//按照分数范围内的数据,从小到发排列,并返回分数
zrangebyscore key min max withscores
//按照分数范围内的数据,从大到小排列,并返回分数
zrevrangebyscore key max min withscores
//查询分数区间内有多少个元素
zcount key min max
//查询某个元素的排名
zrank key value//删除集合中某个元素
zrem key value🎯Hash(哈希)
Redis 的 Hash 是一种键值对集合,类似于编程语言中的字典或哈希表。每个 Hash 包含多个字段(field)和对应的值(value),支持高效的增删改查操作。为了在内存使用与性能之间取得平衡,Redis Hash 根据数据量的不同采用了两种不同的底层实现:ziplist(压缩列表) 和 hashtable(哈希表)。
hset key1 field1 value1 field2 value2
//添加一个值,仅当值不存在时才能添加成功
hsetnx key field value
//集合中某个value自增n
hincrby key field n//获取某个属性值
hget key field
//判断key中某个属性是否存在
hexists key field
//列出集合中所有的field
hkeys key
//列出集合中所有的value
hvals key3.3 数据结构
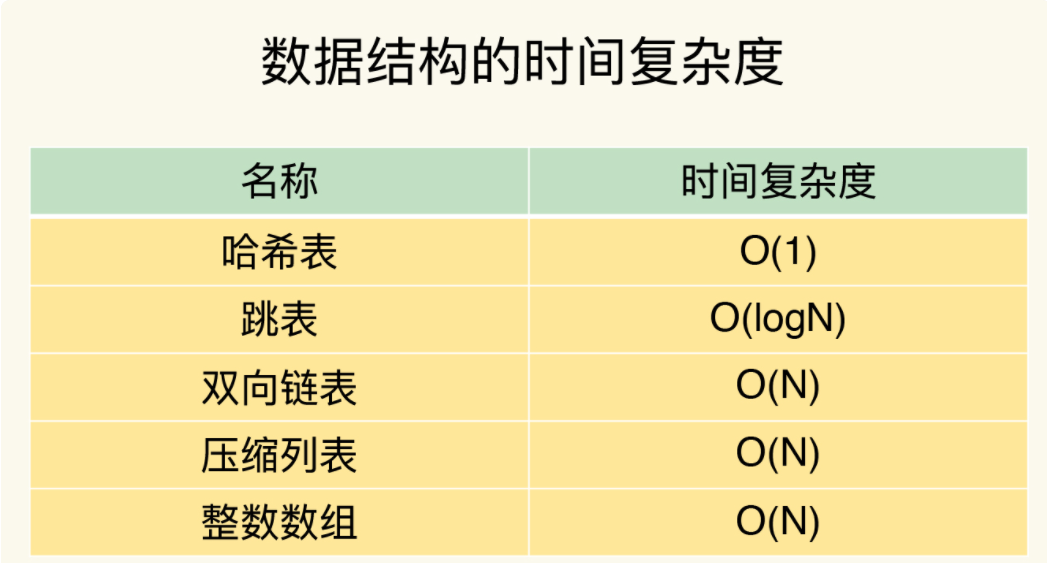
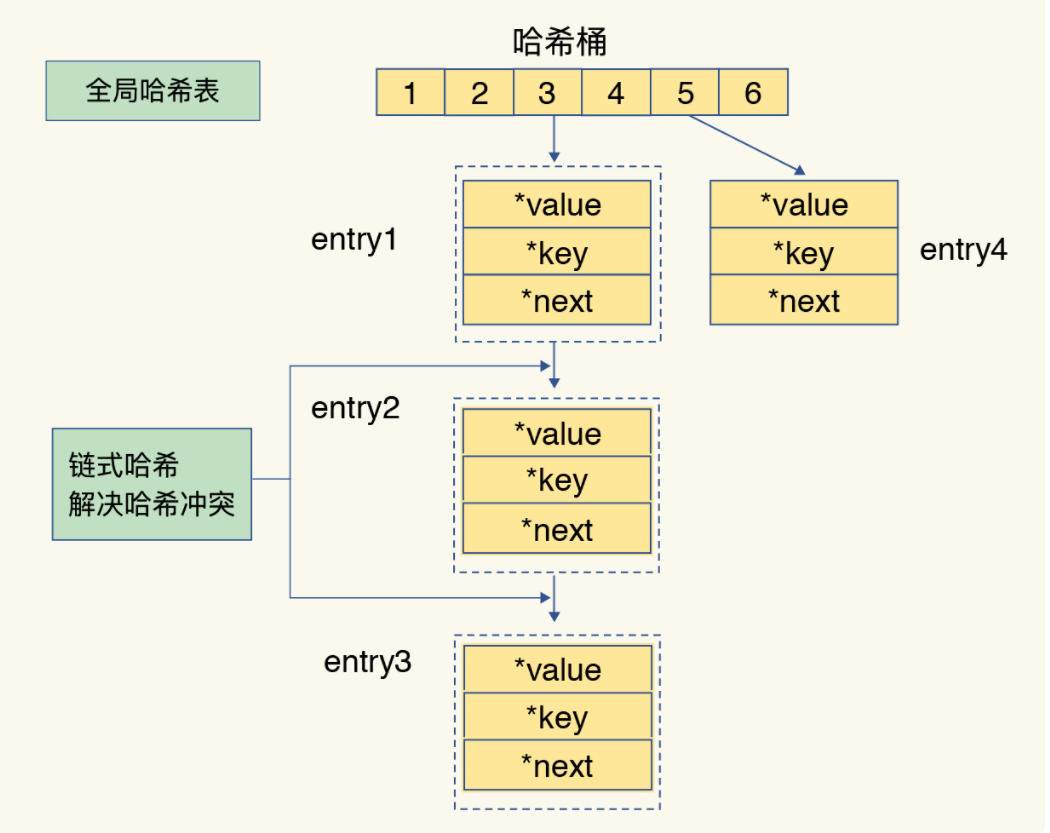
🎯全局哈希表
Redis 的每个数据库(db)都使用一个哈希表(dict)来存储键值对。当客户端执行命令时,Redis 会计算 key 的哈希值,定位到对应的哈希桶,再通过链地址法遍历冲突链查找目标 entry。
随着键值对增多,哈希表的负载因子(load factor)上升,冲突链可能变长,导致查找性能下降。为此,Redis 会触发 rehash 机制:
- 创建一个更大的哈希表(通常为原大小的 2 倍)。
- 采用渐进式 rehash:在后续的每次操作中,顺带将旧表中的一部分键值对迁移至新表。
- 迁移完成后,释放旧表,整个过程不阻塞主线程。
此外,当键被删除或过期时,也可能触发反向 rehash(缩小哈希表),以节省内存。
这种设计在保证高性能的同时,避免了大规模 rehash 带来的延迟尖峰,体现了 Redis 对“低延迟”和“内存效率”的极致追求。
🎯压缩列表
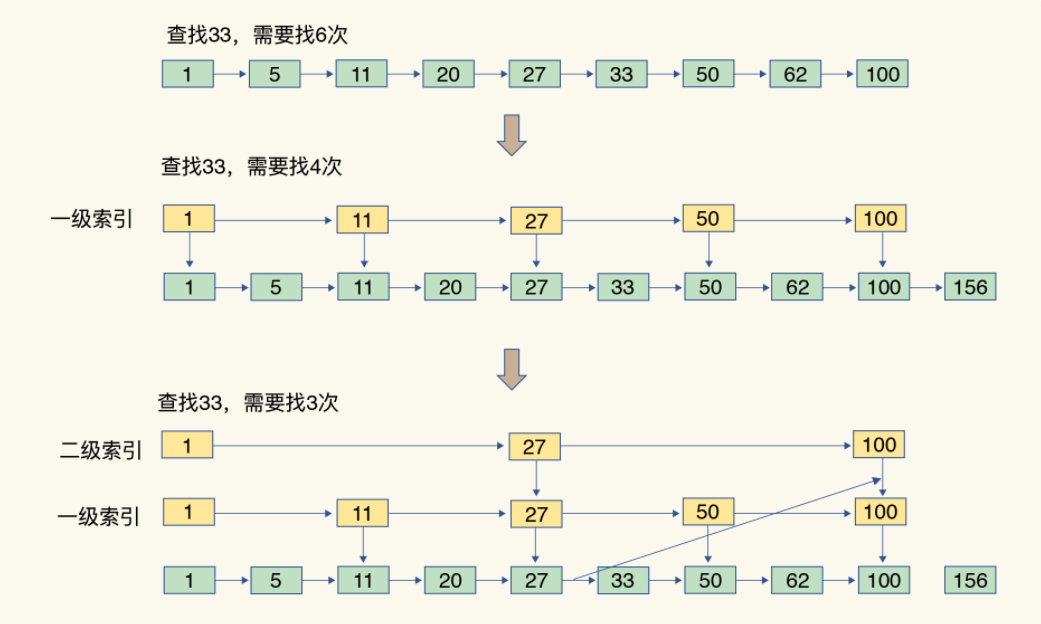
压缩列表类似于一个数组,数组中每一个元素都对应保存一个数据,和数组不同的是,压缩列表在表头有三个字段,分别是列表长度,列表尾的偏移量,列表中entry个数,在表尾还有一个zlend,表示列表结束。在压缩列表中,如果要定位第一个元素和最后一个元素,通过表头三个字段就可以定位,比较高效,而查找其他元素时,只能逐个查找。

🎯跳表
有序链表只能逐一查找元素,导致操作非常慢,于是出现了跳表。具体的说,跳表是在链表的基础上,增加了多级索引,通过索引位置的几个跳转,实现数据的快速定位。