1. 哨兵机制
1.1 概念
Redis Sentinel 是一个用于实现 Redis 高可用(HA) 的分布式系统,它不存储数据,而是监控 Redis 主从节点的运行状态,并在主节点故障时自动完成 故障发现 和 故障转移(failover),选举出新的主节点,通知客户端更新连接地址,从而实现无感切换。
哨兵机制主要负责三个任务:监控、选主、通知。
🎯监控
监控是指哨兵进程在运行时,周期性地给所有的主从库发送 PING 命令,检测它们是否仍然在线运行。如果从库没有在规定时间内响应哨兵的 PING 命令,哨兵就会把它标记为“下线状态”;同样,如果主库也没有在规定时间内响应哨兵的 PING 命令,哨兵就会判定主库下线,然后开始自动切换主库的流程。
🎯选主
主库挂了以后,哨兵就需要从很多个从库里,按照一定的规则选择一个从库实例,把它作为新的主库。这一步完成后,现在的集群里就有了新主库。
🎯通知
在执行通知任务时,哨兵会把新主库的连接信息发给其他从库,让它们执行 replicaof 命令,和新主库建立连接,并进行数据复制。同时,哨兵会把新主库的连接信息通知给客户端,让它们把请求操作发到新主库上。
🎯主观下线和客观下线
哨兵进程会使用 PING 命令检测它自己和主、从库的网络连接情况,用来判断实例的状态。如果哨兵发现主库或从库对 PING 命令的响应超时了,那么,哨兵就会先把它标记为“主观下线”。
如果检测的是从库,那么哨兵简单地把它标记为“主观下线”就行了,因为从库的下线影响一般不太大,集群的对外服务不会间断。但如果是检测的是主库,不能简单地把主库标记为“主观下线”就行了,应该为可能是哨兵误判了。
针对上面的问题,通常会采用多实例组成的集群模式进行部署,这也被称为哨兵集群。引入多个哨兵实例一起来判断,就可以避免单个哨兵因为自身网络状况不好,而误判主库下线的情况。同时,多个哨兵的网络同时不稳定的概率较小,由它们一起做决策,误判率也能降低。
只有大多数哨兵判断主库“主观下线”了,主库才会被标记为“客观下线”,表名主库下线是客观事实了,标准就是当有N个哨兵时,最好有N/2+1个实例判断主库为主观下线,才能最终判定为客观下线。
🎯如何选定新的主库
先按照一定的条件赛选,那些网络总是断连和已经下线的从库直接排除了,然后就是按照规则给从库打分,一共分为三轮,只要某一轮出现了分最高的从库,就可以选举为主库了。
第一轮根据优先级replica-priority配置项,值越小优先级越高(默认 100,0 表示永不选为主)。
第二轮和旧主库同步程度最接近的从库被选为主库,主库有个master_repl_offset,从库有个slave_repl_offset,这是缓存数据的偏移量。正常而言主从库这两个值相等,谁最接近主库,谁分最高。
第三轮,如果前两项相同,则选择 runid 字典序最小的(即启动最早的)。
🎯故障转移的完整流程
- 发现主节点主观下线:某个 Sentinel 发现主节点 ping 不通。
- 确认客观下线:该 Sentinel 向其他 Sentinel 发起投票,多数同意后进入 ODOWN 状态。
- 选举领导者 Sentinel:由一个 Sentinel 发起故障转移,使用 Raft 算法的简化版,第一个进入 ODOWN 的 Sentinel 会尝试拉票,获得多数同意后成为“领导者”。
- 选择新的主节点:从所有健康的从节点中选择一个,选择标准:优先级 > 复制偏移量 > runid 字典序。
- 执行故障转移,向选中的从节点发送
REPLICAOF NO ONE,将其提升为新主。向其他从节点发送REPLICAOF new_master,让它们复制新主。 - 更新配置 & 通知客户端:更新自己的配置。通过 PUBLISH 通知其他 Sentinel。客户端查询 Sentinel 可获取新主地址。
🎯旧的主节点恢复会怎么样
初始状态:
Master(M): 写入 key1, key2, key3
Replica(R): 同步了 key1, key2(还没来得及同步 key3)M 宕机,Sentinel 触发故障转移,选举 R 为新主,新主 R 开始对外提供服务,接收新写入(比如 set key4 100)。
M 重启,发现自己不再是主节点,M 通过 Sentinel 获取到新的主节点是 R,M 自动将自己降级为 从节点,并向 R 发起复制请求。
M 上的 key3 会被彻底覆盖!M 会完全同步 R 的数据状态,变成 R 的从节点。
🎯Redis Sentinel 是 AP 还是 CP?
| 维度 | 表现 | 倾向 |
|---|---|---|
| P(分区容忍) | 支持跨机房部署,容忍网络分区 | ✅ 必须支持 |
| A(可用性) | 主节点故障后,自动选主,快速恢复服务 | ✅ 强调高可用 |
| C(一致性) | 无法保证强一致性(异步复制) | ⚠️ 弱一致性(最终一致) |
所以:Redis Sentinel 是 AP 系统。但它可以通过配置(如 min-replicas-to-write)增强一致性保障,向 CP 靠拢,变成“有条件的一致性”。
🎯客户端如何感知主节点变化
客户端不能直接写死主节点地址,必须通过以下方式获取:
- 连接 Sentinel 集群,发送
SENTINEL get-master-addr-by-name [master-name]命令,获取当前主节点 IP 和端口。 - 监听 Sentinel 的 +switch-master 事件,一旦发生主从切换,立即更新本地连接。
常见客户端支持:
- Jedis:JedisSentinelPool
- Lettuce:原生支持 Sentinel
- Redisson:内置 Sentinel 支持
1.2 哨兵集群
哨兵集群,即使有哨兵实例出现了故障,其他哨兵还能继续协作完成主从库切换工作,判断主库是否下线、选择新的主库、通知从库和客户端。
🎯集群配置文件(windows)
# 当前Sentinel服务运行的端口
# 在默认情况下,Sentinel 使用 TCP 端口 26379(普通 Redis 服务器使用的是 6379 )
port 26379
# 哨兵监听的主节点mymaster;最后面的数字 2 表示最低通过票数;# 默认值 2
# 如果投票通过,则哨兵群体认为该主节点客观下线(+odowm)
sentinel monitor mymaster 127.0.0.1 6379 2
# 哨兵认定当前主节点mymaster失效的判别间隔时间
# 如果在设置的时间内(毫秒),当前主节点没有响应或者响应错误代码,则当前哨兵认为该主节点主主观下线(sdown)
# 3s内mymaster无响应,则认为mymaster宕机了
sentinel down-after-milliseconds mymaster 3000
# 执行故障转移时,最多有1个从节点同时对新的主节点进行同步
# 当新的master上位时,允许从节点同时对新主节点进行同步的从节点个数;默认是1,建议保持默认值
# 在故障转移期间,将会终止客户端的请求
# 如果此值较大,则意味着"集群"终止客户端请求的时间总和比较大
# 反之此值较小,则意味着"集群"在故障转移期间,多个从节点仍可以提供服务给客户端
sentinel parallel-syncs mymaster 1
# 故障转移超时时间。
# 当故障转移开始后,但是在此时间内仍然没有触发任何故障转移操作,则当前哨兵会认为此次故障转移失败
sentinel failover-timeout mymaster 10000port 26379
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 3000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 10000port 26380
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 3000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 10000port 26381
sentinel monitor mymaster 127.0.0.1 6379 2
sentinel down-after-milliseconds mymaster 3000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 10000redis-server sentinel6379.conf --sentinel
redis-server sentinel6380.conf --sentinel
redis-server sentinel6381.conf --sentinelredis-cli -p 26379info sentinel🎯哨兵集群是如何通信的
Redis提供了发布订阅机制:每个哨兵只要和主节点建立了连接,就可以在主节点上发布消息(IP和端口)。同时也可以从主节点订阅消息,获得其他哨兵发布的连接信息。当多个哨兵实例都在主库上做了发布订阅之后,它们之间就能知道彼此的连接信息了。
每个 Sentinel 每秒向其他 Sentinel 发送 PING 消息,交换对主从节点的健康判断。
当某个 Sentinel 更新了主从配置(如主从切换后),会通过 Gossip 传播给其他 Sentinel。
🎯哨兵实例是如何知道从库信息的
这是哨兵向主库发送info命令来完成的,获取从库列表,和每个从库建立连接,并进行监控。
🎯Sentinel 集群至少需要几个节点?为什么?
至少 3 个 Sentinel 节点,推荐 3 或 5 个,且为奇数。
- 为了实现“多数派”投票(quorum),避免脑裂。
- 2 个 Sentinel:挂一个就无法形成多数,失去高可用。
- 3 个 Sentinel:允许挂 1 个。
- 5 个 Sentinel:允许挂 2 个。
🎯基于发布订阅机制的客户端事件通知
本质上说,哨兵就是运行在特别模式下的Redis实例,每个哨兵也提供了发布订阅机制,客户端可以从哨兵订阅消息,哨兵提供的消息订阅频道有很多,不同的频道包含了主从库切换过程中的不同关键事件。
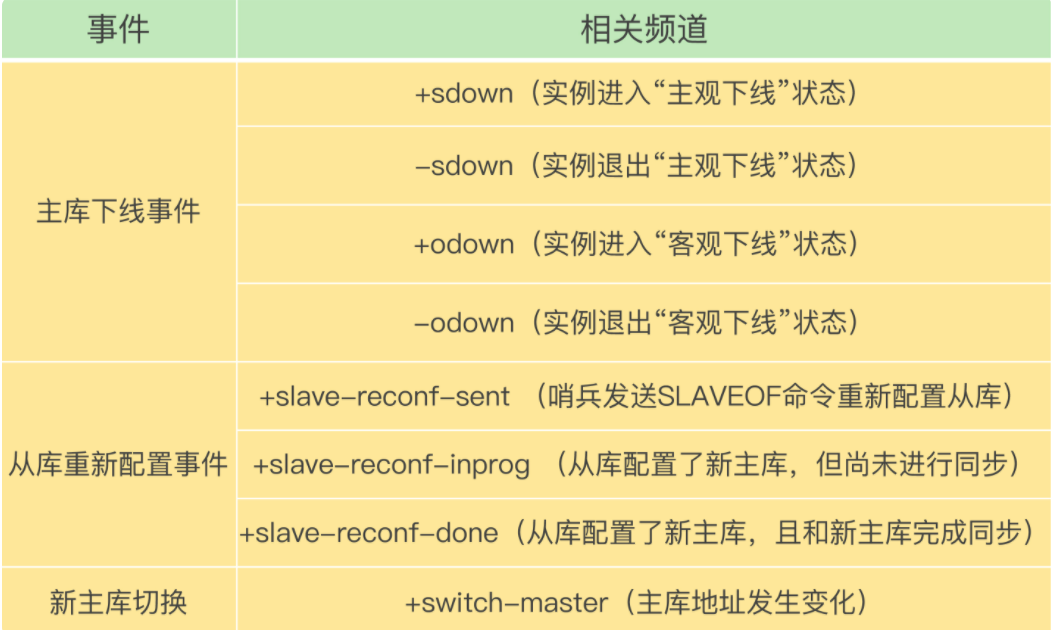
🎯一个主库是如何被客观下线的
任何一个哨兵判断主库主观下线之后,就会给其他实例发送命令,其他实例也会根据自己和主库的连接情况,做出赞成或是反对,一个哨兵获得了仲裁所需的赞成票数后,就可以标记主库为客观下线。这个所需的赞成票数是通过哨兵配置文件中的quorum配置项设定的。例如,现在有5个哨兵,quorum 配置的是3,那么,一个哨兵需要3张赞成票,就可以标记主库为“客观下线”了。这3张赞成票包括哨兵自己的一张赞成票和另外两个哨兵的赞成票。
🎯由哪个哨兵执行主从切换
在主库客观下线之后,哨兵就会给其他哨兵发送命令,表明希望由自己来执行主从切换,并让其他哨兵进行投票,这个投票过程称为Leader选举。任何一个想要成为leader的哨兵要满足两个条件,一是拿到半数以上的赞成票,二是拿到的票数还要大于等于哨兵配置文件中的quorum值。
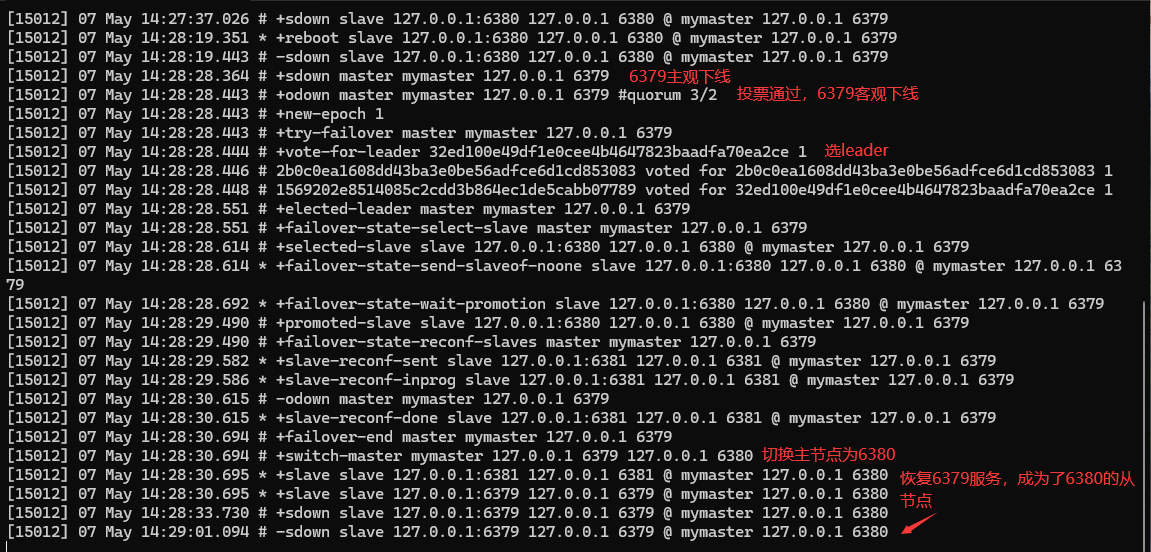
🎯测试
测试模型为一主两从,主节点为6379,从节点分别为6380和6381。首先是测试从节点故障,把6380服务关闭,哨兵会显示+sdown slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379,代表6380已经主观下线了,由于6380是从节点,所以主观下线就可以了;然后重启6380服务,哨兵会显示 -sdown slave 127.0.0.1:6380 127.0.0.1 6380 @ mymaster 127.0.0.1 6379,代表6380退出主观下线状态,从节点6380恢复服务。
下面的图片标注的内容,是测试主节点6379故障,把6379服务关闭:
- 哨兵首先判断出6379主观下线,
- 接下来哨兵集群投票6379客观下线,
- 然后就是选举哨兵leader,
- 接着就是切换主节点为6380,同时redis服务和sentinel服务的配置文件也会相应改变。
- 然后我们手动恢复6379服务,哨兵提示6379退出了主观下线状态,变成了6380的一个从节点。
1.3 脑裂
🎯脑裂场景
当 Redis 集群因网络分区(Network Partition) 导致主从节点被隔离在不同网络区域时,Sentinel 可能会在多个区域分别选举出“新主节点”,从而出现多个主节点同时存在的现象,这就是“脑裂”。
多个客户端可能同时向不同的“主节点”写入数据。数据不一致,甚至覆盖丢失。系统恢复后数据难以合并,可能导致严重业务事故。
假设我们有以下架构:
机房A(北京) 机房B(上海)
----------------- -----------------
Master (M) | Replica (R1)
| Replica (R2)
Sentinel (S1) | Sentinel (S2)
| Sentinel (S3)- M 和 S1 在北京机房
- R1、R2、S2、S3 在上海机房
- 所有节点正常时:M 为主,R1、R2 为从
⚡** 突发:北京与上海之间网络中断!**
✅** 北京机房视角:**
- S1 能 ping 通 M,认为 M 正常。
- S1 无法与 S2、S3 通信,但 M 还活着 → 不触发故障转移
✅ 上海机房视角:
- S2、S3 无法 ping 通 M(超时)
- S2 和 S3 达成多数(2/3),判定 M 客观下线
- S2/S3 开始故障转移:
- 选择 R1 为新主
- 执行 REPLICAOF NO ONE,R1 成为新主
- 上海机房现在有一个“新主”:R1
🚨** 脑裂发生!**
北京机房:M 仍然是主(接受写入)
上海机房:R1 是新主(也接受写入)🎯解决方案
Redis 提供了两个关键配置,用于限制主节点的写入条件,从而避免在网络分区时继续服务:
✅ 核心配置(必须在主节点上设置):
# 最少从节点数量,低于此数则拒绝写入
min-replicas-to-write 1
# 从节点延迟最大允许秒数(配合上一条使用)
min-replicas-max-lag 10只有当至少有 1 个从节点,并且它们的复制延迟(lag)小于 10 秒时,主节点才允许执行写命令。否则,主节点会拒绝所有写操作,返回错误:
(error) WRITE commands are not allowed against a write master with not enough replicas.1.4 整合Springboot
🎯配置
这段配置是 Spring Data Redis 的标准配置方式,适用于 Lettuce 和 Jedis。但是,默认情况下,Spring Boot 使用的是 Lettuce 作为其 Redis 客户端。这是因为自 Spring Data Redis 2.x 版本以来,默认客户端从 Jedis 更改为 Lettuce。
注意配置主从模式的时候,不要设置单个的redis配置,这样会使主从配置失效。
spring:
redis:
timeout: 5000
host: 127.0.0.1
port: 6379spring:
redis:
timeout: 5000
sentinel: #通过配置哨兵可以实现客户端对主从模式的监听
master: mymaster
nodes: 127.0.0.1:26379,127.0.0.1:26380,127.0.0.1:26381🎯Springboot下RedisTemplate的序列化配置
为Redis的键-值设置序列化器,也为Redis中哈希类型的哈希键-哈希值设置序列化器。如果没有这个全局配置,就需要每次手动序列化,例如我想给key为user设置一个Student对象,我就需要手动把Student对象序列化为字符串进行保存,然后读取的时候又反序列化为Student对象。如果有了下面的全局配置,我可以直接把Student对象设置为value,读取的时候也可以自动转化为Student对象。
@Configuration
public class RedisConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) throws UnknownHostException {
RedisTemplate<String, Object> template = new RedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer(objectMapper);
//设置key
template.setKeySerializer(RedisSerializer.string());
template.setHashKeySerializer(RedisSerializer.string());
//设置value
template.setValueSerializer(jsonRedisSerializer);
template.setHashValueSerializer(jsonRedisSerializer);
return template;
}
}