1. 四种集群方案
1.1 集群部署
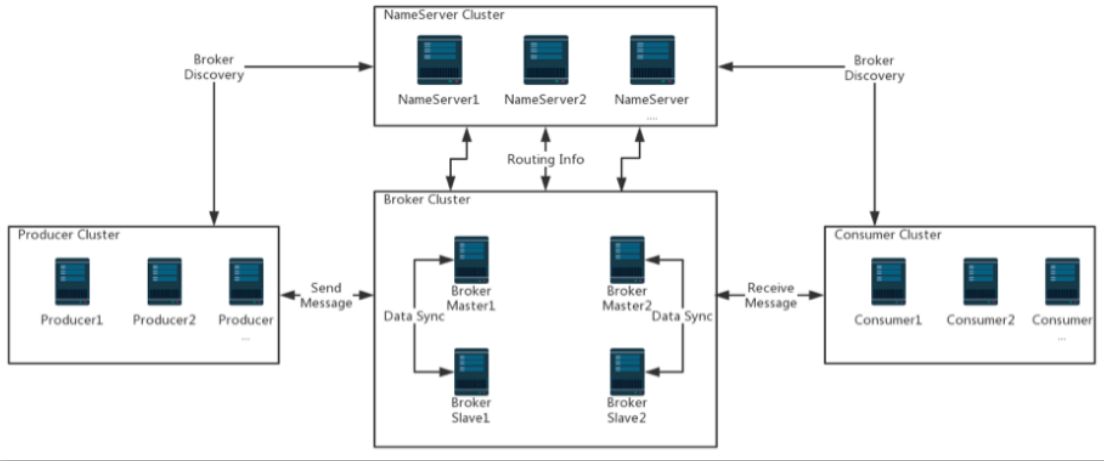
- 多Master模式:一个集群无Slave,全是Master,例如两个或者三个Master
- 多Master多Slave模式-异步复制:每一个Master配置一个Slave,有多对这样的组合,HA采用异步复制的方式,主备有短暂的消息延迟,毫秒级别。
- 多Master多Slave模式-同步双写:每一个Master配置一个Slave,有多对这样的组合,HA采用同步双写的方式,只有主备都写成功了,才响应客户端。
- Dledger部署:每个master配置两个slave组成DledgerGroup,可以有多个DledgerGroup,由Dledger实现Master的选举。
1.2 多Master模式
🎯原理
- 所有节点都是 Master 节点,没有 Slave。
- 每个 Master 独立承担消息的读写请求。
- Broker 启动时只配置 brokerId=0(表示是 Master),不配置从节点。
🎯优点
- 架构简单,部署维护方便。
- 写性能极高:所有节点都可写,无主从同步开销。
- 异步刷盘丢失少量消息,同步刷盘一条不丢。
- 无单点故障(只要有一个 Master 存活,系统就能收发消息)。
🎯缺点
无数据副本,存在消息丢失风险:如果某个 Master 宕机且磁盘损坏,该节点上的消息将永久丢失。
不支持主从切换,宕机即服务不可用,绑定在该服务上的Topic队列无法被消费者继续消费。
1.3 多Master多Slave模式-异步复制
🎯原理
- 每个 Master 配置一个或多个 Slave。
- Master 和 Slave 通过 异步方式 同步数据(CommitLog 复制)。
- Slave 只读,不参与写入,可用于消息消费(开启 slaveReadEnable)或故障转移。
🎯优点
- 数据有副本,提高了可靠性。
- 写性能依然很高:主从复制为异步,不影响主节点响应速度。
- 支持读写分离(Slave 可承担部分消费请求),提升整体吞吐量。
- 主节点宕机后,可手动或自动切换到 Slave(需配合 Dledger 或外部高可用组件)。
🎯缺点
- 存在数据丢失风险:如果 Master 宕机且未完成同步,未复制到 Slave 的消息会丢失。
- 故障切换需要时间(不能完全自动,除非使用 Dledger 组合)。
🎯Master正常时Slave读能力
在 RocketMQ 配置中,有一个参数 slaveReadEnable,默认是 false。如果设置为 true,则允许消费者从 Slave 节点拉取消息。
RocketMQ 通过以下几种方式避免主从同时提供读服务时可能出现的冲突:
- 无论是从 Master 还是从 Slave 拉取消息,每个 Consumer Group 都会有自己的消费进度(Offset)。这意味着即使从不同的节点读取数据,RocketMQ 也能保证每个 Consumer Group 按照自己的进度独立地进行消费,不会产生冲突。
🎯Master故障时Slave读能力
在纯异步复制模式下,Slave 节点虽然可以通过 slaveReadEnable 开启读能力,但在 Master 宕机后,由于 NameServer 不会自动更新路由,消费者也无法自动感知应切换到 Slave,因此无法实现自动故障转移。这意味着服务仍然会中断。
要实现真正的高可用,必须引入 Dledger 集群模式,通过 Raft 协议实现自动选主和路由切换,才能做到故障对上下游透明。
1.4 多Master多Slave模式-同步双写
🎯原理
Master 接收到消息后,必须同步等待 Slave 写入成功(CommitLog 落盘或写入 PageCache),才返回生产者“发送成功”。
🎯优点
- 强数据一致性与高可靠性:确保主从数据一致,即使 Master 宕机,Slave 也有完整数据。
- 极大降低消息丢失概率(接近 0)。
🎯缺点
- 性能下降明显:RT(响应时间)增加,TPS 下降,因为要等待网络 + Slave 写盘。
- 备机不能自动切换为主机。
1.5 Dledger模式
DLedger 是 RocketMQ 4.5+ 引入的基于 Raft 共识算法 实现的分布式日志存储模块。DLedger 是一个专为 RocketMQ CommitLog 设计的 Raft 日志复制库,它将消息写入抽象为“状态机变更”,通过 Raft 协议保证多副本间的数据一致性与高可用性。
🎯架构模型
DLedger Group(复制组):
- 由多个(通常为奇数个,如 3/5)物理节点组成,构成一个 Raft 复制组。
- 每个组对应一个 dLegerGroup,独立运行 Raft 协议。
- 在 RocketMQ 中,一个 brokerName 对应一个 DLedger Group,即一组主从节点由 Raft 动态选举产生。
节点角色(动态):
- Leader:唯一可接受客户端写请求的节点,负责日志条目(Log Entry)的 Append 和复制。
- Follower:被动接收 Leader 的 AppendEntries 请求,持久化日志并返回确认。
- Candidate:在选举期间临时存在,发起投票请求。
Quorum 机制:
- 写操作需在 多数派节点 成功落盘后才向客户端返回成功。
- 对于 N 个节点的集群,最多容忍 (N-1)/2 个节点故障。
🎯Leader 选举
触发条件:
- 初始启动(所有节点为 Follower)
- Leader 心跳超时(electionTimeout,默认 250ms~500ms 随机)
- 网络分区恢复
流程:
- Follower 转为 Candidate,递增当前 Term,发起投票请求(RequestVote)。
- 接收方根据 Term 单调性 + 日志完整性(Last Log Index/Term) 判断是否投票。
- 若 Candidate 获得 Quorum 投票,则晋升为 Leader,并立即向所有 Follower 发送空 AppendEntries(心跳),确立领导地位。
🎯日志复制
写流程(Producer 发送消息):
- 客户端请求发送至 Leader。
- Leader 将消息封装为 DLedger Log Entry,写入本地 CommitLog(追加到 MappedFile),并记录 pendingIndex。
- 并行向所有 Follower 发送 AppendEntries 请求,包含新日志条目。
- Follower 接收后:
- 校验 Term 和前序日志匹配(prevLogIndex/prevLogTerm)
- 持久化日志到本地 CommitLog
- 返回 AppendReply
- Leader 收集响应,当 超过半数节点(含自己)确认,即达成 Quorum。
- Leader 将该日志条目标记为 Committed,更新 commitIndex,并通知本地存储模块触发刷盘(可配置异步/同步刷盘)。
- 向客户端返回 SEND_OK。
🎯数据一致性保障
- 只有 Leader 可追加日志,Follower 被动复制。
- 通过 prevLogIndex/prevLogTerm 保证日志序列一致性。
- 新 Leader 必须包含所有已 Committed 的日志条目(因选举时投票条件限制)。
- Follower 落后日志:Leader 会触发 Log Truncation & Snapshot Sync 补齐
- 网络分区恢复:旧 Leader 会收到新 Term 的心跳,自动降级为 Follower。
🎯读可用性优化
- 默认情况下,所有读写均由 Leader 处理。
- 可配置 enableSlaveActingMaster=true 或通过客户端指定 readFromFollower=true,允许消费者从 Follower 拉取消息。
- Follower 拉取时基于本地 committedIndex 返回数据,保证不会读到未提交消息,但可能存在轻微延迟(最终一致性读)。
🎯与 RocketMQ 的集成
- CommitLog 替换:DLedgerCommitLog 替代原生 CommitLog,所有消息写入走 DLedger 流程。
- 元数据同步:Broker 的 Topic 路由信息仍通过 NameServer 同步,但 Broker 角色(Leader/Follower)由 DLedger 内部维护。
- 故障透明性:
- NameServer 检测到 Broker 心跳异常,触发路由剔除。
- 客户端(Producer/Consumer)通过 MQClientInstance 的定时任务拉取最新路由,自动切换至新 Leader。
| 层面 | 接管方式 |
|---|---|
| 写入入口 | DLedgerCommitLog.putMessage()拦截写请求,交由 DLedger 处理 |
| 数据复制 | 替代 HAService,通过 Raft 实现强一致复制 |
| 角色管理 | 替代 BrokerRoleManager,由 Raft 选举动态决定 Leader/Follower |
| 高可用 | 故障自动转移,客户端通过路由更新无感切换 |
| 接口兼容 | 对上层模块(Store、Consumer)保持 CommitLog 接口不变 |
🎯高可用
三个 NameServer 极端情况下,确保集群的可用性,任何两个 NameServer 挂掉也不会影响信息的整体使用。在上图中每个 Master Broker 都有两个 Slave Broker,这样可以保证可用性,如在同一个 Dledger Group 中 Master Broker 宕机后,Dledger 会去行投票将剩下的节点晋升为 Master Broker。
🎯高并发
假设某个Topic的每秒十万消息的写入, 可以增加 Master Broker 然后十万消息的写入会分别分配到不同的 Master Broker ,如有5台 Master Broker 那每个 Broker 就会承载2万的消息写入。
🎯可扩展
如果消息数量增大,需要存储更多的数量和最高的并发,完全可以增加 Broker ,这样可以线性扩展集群。一个Topic的队列分散在不同的Broker上面。
🎯海量信息
数据都是分布式存储的,每个Topic的数据都会分布在不同的 Broker 中,如果需要存储更多的数据,只需要增加 Master Broker 就可以了。