1. RocketMQ核心概念
1.1 RocketMQ 核心组件架构概述
RocketMQ 主要由 Producer(生产者)、Broker(消息服务器) 和 Consumer(消费者) 三大部分构成,共同实现消息的发布、存储与订阅。
- Producer:负责创建并发送消息到指定的 Topic。一个生产者可以向多个 Topic 发送消息。
- Consumer:负责从 Topic 中拉取消息并进行处理。消费者通常以 Consumer Group(消费者组) 的形式组织,每个 Consumer Group 由一个或多个 Consumer 实例组成,支持集群消费或广播消费模式。
- Broker:是消息中转节点,负责消息的接收、存储与转发。在部署中,每个 Broker 对应一台独立的服务器。单个 Broker 可以存储多个 Topic 的消息,而每个 Topic 的消息也可以通过分片机制分布到多个 Broker 上,实现水平扩展。
消息在 Broker 中的存储以 Topic 为逻辑单位,每个 Topic 被划分为一个或多个 MessageQueue(消息队列),作为消息存储的物理单元。MessageQueue 是负载均衡和并行消费的基本单位,Topic 的消息会均匀分布在其所属的多个 MessageQueue 中。
1.2 消息生产者
🎯概念
生产者(Producer) 是消息的发送方,通常由业务系统中的应用模块充当。其主要职责是将业务运行过程中产生的事件或数据封装为消息,并发送到指定的 Broker 服务器中。
RocketMQ 提供了多种消息发送方式,适用于不同场景:
- 同步发送(Sync Send):生产者发送消息后阻塞等待 Broker 返回确认(ACK),适用于对可靠性要求高、可接受一定延迟的场景(如订单创建)。
- 异步发送(Async Send):发送消息后不阻塞,通过回调函数接收发送结果,适用于高吞吐、低延迟场景(如日志收集)。
- 单向发送(Oneway Send):只发送消息,不等待任何响应,适用于对可靠性要求不高的场景(如监控数据上报)。
- 顺序发送(Ordered Send):保证同一队列(MessageQueue)中的消息按发送顺序被消费,适用于有顺序要求的业务(如订单状态变更)。
在 RocketMQ 中,同一类生产者可以被组织成一个逻辑集合,称为“生产者组(Producer Group)”。同一组内的所有生产者实例被视为发送同一类消息、具备相同业务逻辑和配置的节点,常用于实现分布式环境下消息发送的统一管理和故障转移。
🎯生产者组
Producer Group 是 RocketMQ 中用于逻辑归类、统一管理和实现高可用的“生产者身份标签”,尤其在事务消息和分布式部署中不可或缺。如果没有 Producer Group,Broker 就不知道该找谁回查!
- 在“半消息”机制中,Broker 通过 Producer Group 来标识事务的发起方,确保事务状态回查能正确路由到对应的生产者实例。
- 在 ACL(访问控制)体系中,权限可以按 Producer Group 粒度分配,例如只允许 OrderProducerGroup 向 TOPIC_ORDER 发送消息。
场景一:订单系统集群部署
- 你有 3 台应用服务器部署了订单服务。
- 每台服务器都启动了一个 Producer 实例。
- 它们都设置为同一个 Group:OrderProducerGroup
- 这样,即使其中一台宕机,另外两台仍可继续发送“订单创建”消息,且事务状态回查能正确找到任意一个在线实例。
场景二:事务消息
- 你在 A 系统中发了一个事务消息,Group 是 TxGroupA
- Broker 保存了这条“半消息”,并在超时后发起事务回查
- 回查请求会发送给 TxGroupA 下任意一个在线的 Producer 实例(通过 NameServer 路由)
- 该实例调用 executeLocalTransaction 或 checkLocalTransaction 返回事务状态
🎯消息类型与重试机制
RocketMQ 支持三种主要的消息发送模式,对应不同的有序性保障级别。
消息重试机制仅对“普通消息”生效。对于有序消息(普通或严格),一旦发送失败,默认不会自动重试到其他队列,否则会破坏顺序性。
| 类型 | 说明 |
|---|---|
| 普通消息 | 消息无序,可发送到 Topic 的任意 MessageQueue,适用于大多数异步解耦场景。 |
| 普通有序消息 | 同一类消息(如同一用户 ID)通过哈希算法固定发送到同一个 MessageQueue,保证单队列内有序。在异常情况下允许短暂乱序,恢复后重新有序。 |
| 严格有序消息 | 所有消息必须发送到同一个 MessageQueue,即使该队列所在 Broker 宕机,也不允许切换队列,必须等待其恢复,确保全局强有序。 |
普通消息的发送与重试机制
对于普通消息,RocketMQ 提供了高可用的发送策略和智能重试机制:
- 负载均衡策略
- 默认采用 Round-Robin(轮询) 方式选择 MessageQueue,实现消息在多个队列间的均匀分布。
- 失败重试机制
- 发送失败时,默认最多重试 2 次(可通过 retryTimesWhenSendFailed 配置)。
- 重试时会避开上一次发送失败的 Broker,优先选择其他正常的 Broker。
- 如果集群中仅有一组 Master/Slave(即该 Topic 只分布在一对 Broker 上),则只能在该组内的其他 MessageQueue 中重试。
- 智能路由优化,为提升发送成功率与性能,RocketMQ 内置两种策略
- 失败隔离,若某 Broker 发送失败,将其临时标记为“不可用”,后续发送优先避开该节点,避免连续失败。
- 延迟隔离,根据历史调用延迟动态调整 Broker 权重,优先选择响应更快的节点,提升整体吞吐。
普通有序消息的容错与短暂无序
对于普通有序消息,其核心原则是:相同业务 Key 的消息始终发送到同一个 MessageQueue。
正常情况:
使用 key % queueCount 的哈希算法确定目标队列。例如:
int queueId = Math.abs(user.getId().hashCode()) % messageQueues.size();同一用户的消息始终落在同一队列,保证有序。
异常情况(Broker 宕机):
- 客户端从路由表中移除该 Broker 下的所有 MessageQueue。
- 哈希计算结果可能指向另一个 Broker 上的队列,导致该用户后续消息发送到新队列。
- 此时会出现短暂乱序(新旧队列消息交错)。
- 但在此之后,该用户的所有消息将稳定发送到新队列,恢复局部有序。
严格有序消息的强一致性要求
严格有序消息要求所有消息必须发送到同一个物理队列,即使该队列不可用:
- 当目标 MessageQueue 所在 Broker 宕机时:
- 生产者不会尝试发送到其他队列。
- 发送操作将持续阻塞或失败,直到原 Broker 恢复。
🎯普通消息发送
这是最基础的发送方式,RocketMQ 默认就是这种模式。
// 同步发送
SendResult result = producer.send(msg);
// 异步发送
producer.send(msg, new SendCallback() { ... });
// 单向发送
producer.sendOneway(msg);- 无需特殊设置,直接调用即可。
- 默认使用轮询(Round-Robin)选择 MessageQueue。
- 支持重试机制(可通过 retryTimesWhenSendFailed 配置)。
🎯普通有序消息
RocketMQ 提供了专门的 API 来实现基于业务 Key 的有序发送。
// 发送有序消息
SendResult result = producer.send(msg, new MessageQueueSelector() {
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
Integer userOrderId = (Integer) arg;
int index = userOrderId % mqs.size();
return mqs.get(index);
}
}, orderId); // orderId 作为 arg 传入- MessageQueueSelector:你提供选择逻辑,比如按 orderId % queueCount。
- arg:传入业务 Key(如用户 ID、订单 ID)。
- RocketMQ 会确保相同 arg 的消息尽可能发送到同一个队列
🎯严格有序消息
所谓的“严格有序”,是你在使用 普通有序消息 API 时,人为施加的一种使用约束:
- 你只创建 一个 MessageQueue(queueNum=1)
- 然后使用 MessageQueueSelector 固定发送到 mqs.get(0)
- 当这个队列的 Broker 宕机时,你不做任何容错,必须等待它恢复
// 强制所有消息发送到第一个队列(且只有一个队列)
SendResult result = producer.send(msg, new MessageQueueSelector() {
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
return mqs.get(0); // 始终选择第一个队列
}
}, null);同时创建 Topic 时指定队列数为 1:
# 创建 Topic,只分配 1 个队列
sh mqadmin updateTopic -n 127.0.0.1:9876 -t ORDER_TOPIC -r 8 -w 11.3 消息消费者
🎯概念
消费者(Consumer)是消息的接收与处理方,通常由后台系统以异步方式运行,负责从 Broker 服务器拉取消息并交由应用程序进行业务处理。它是实现系统解耦、异步处理和流量削峰的关键组件。
RocketMQ 从应用控制视角提供了两种消息消费模式:拉取式消费(Pull Consumption) 和 推动式消费(Push Consumption),分别适用于不同的业务场景与实时性要求。
🎯拉取式消费
应用程序主动调用 Consumer 的 pull() 或 pullBlockIfNotFound() 等接口,从 Broker 定期或按需拉取消息。消费的时机、频率和批量大小由应用完全控制。
🎯推动式消费
虽然名为“推送”,但 RocketMQ 的“推动式消费”实际上是 基于长轮询(Long Polling)的伪推送机制。
Consumer 向 Broker 发起拉取请求后,若无消息,Broker 会将请求挂起(最长可配置),直到有新消息到达或超时,再立即返回响应,从而模拟“推送”效果。
🎯消费者组
在 RocketMQ 中,多个具有相同业务目标的消费者实例可以被组织成一个逻辑集合,称为 消费者组(Consumer Group)。组内所有消费者通常订阅相同的 Topic,并采用一致的消息处理逻辑。
- 即使系统中只有一个消费者实例,也应将其归入一个消费者组,以便统一管理和维护消费状态。
- 每个消费者组拥有一个全局唯一的组名(Consumer Group Name),用于标识其身份。
- Broker 端会持久化该组的消费进度(消费位点,Consumer Offset)。当消费者实例重启、扩容或缩容时,新实例可通过组名恢复之前的消费位置,避免消息重复或丢失。
🎯集群消费模式
- 定义:同一消费者组内的多个消费者实例共同分摊该组订阅 Topic 的全量消息,每条消息仅被组内任意一个消费者成功处理。
- 负载均衡:RocketMQ 通过 Rebalance 机制,将 Topic 下的 MessageQueue 均匀分配给组内各消费者实例,实现并行消费与横向扩展。
- 容错机制:若某个消费者实例宕机,其所负责的 MessageQueue 会自动重新分配给组内其他存活实例,确保消息不中断。
示例:
- Topic 有 4 个 MessageQueue
- Consumer Group 有 2 个实例
- 每个实例消费 2 个队列 → 实现负载均衡
🎯广播消费模式
- 定义:同一消费者组内的每个消费者实例都接收并处理全量消息,即每条消息会被组内所有实例各消费一次。
- 消费进度:不依赖 Broker 维护,每个消费者实例自行维护本地消费位点(如内存或本地文件)。
- 重启行为:客户端每次重启后,默认从最新消息开始消费(可配置)。
- 适用场景:需要全局通知或本地状态同步的场景,如缓存刷新、配置更新、监控告警等。
🎯消费者组的意义
- 水平扩展,弹性扩容:通过在消费者组内增加消费者实例,可实现消费能力的水平扩展。当消息量增长时,只需动态添加消费者,即可提升整体吞吐,轻松应对流量高峰。
- 高可用容灾,自动恢复:单个消费者实例故障时,RocketMQ 会自动触发 Rebalance(重平衡),将其负责的消息队列重新分配给组内其他健康实例,实现无缝故障转移,保障系统持续稳定运行。
- 并行消费,高效处理:消息队列天然支持并行处理。消费者组中的多个实例可并行消费不同队列的消息,大幅提升消费速度。但同一队列的消息只会被组内一个消费者消费,由 RocketMQ 内部机制严格保证,避免重复消费。
🎯使用集群模式模拟广播
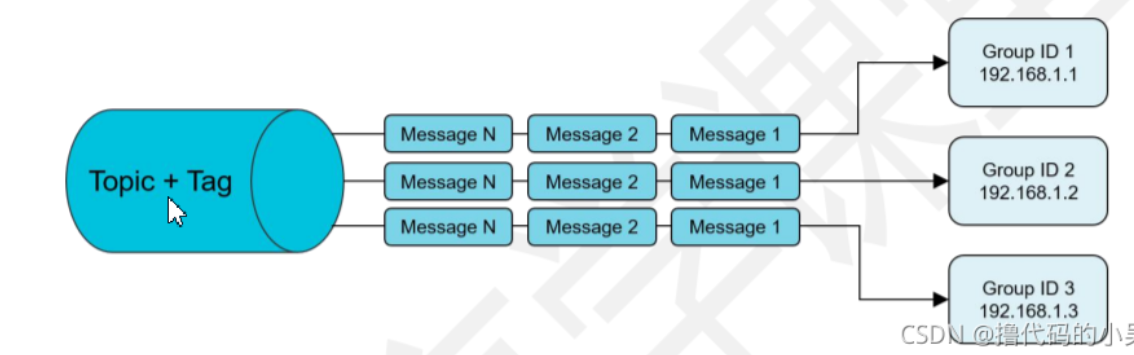
如果业务需要使用广播模式,也可以创建多个 Group ID,用于订阅同一个 Topic。
- 每条消息都需要被多台机器处理,每台机器的逻辑可以相同也可以不一样。
- 消费进度在服务端维护,可靠性高于广播模式。
- 对于一个 Group ID 来说,可以部署一个消费端实例,也可以部署多个消费端实例。当部署多个消费端实例时,实例之间又组成了集群模式(共同分担消费消息)。 假设 Group ID 1 部署了三个消费者实例 C1、C2、C3,那么这三个实例将共同分担服务器发送给 Group ID 1 的消息。 同时,实例之间订阅关系必须保持一致。
1.4 Topic
Topic 是一类消息的集合,是 RocketMQ 中消息发布与订阅的基本单位。每条消息在发送时必须指定一个 Topic,且只能属于一个 Topic。
用于对消息进行逻辑分类,例如:ORDER_TOPIC(订单)、PAYMENT_TOPIC(支付)、LOG_TOPIC(日志)等,生产者和消费者通过 Topic 实现解耦与通信。
🎯关键特性
- 逻辑概念:Topic 本身并不存储消息,它只是一个逻辑上的分类标签。
- 分布式存储:同一个 Topic 的消息会被分片存储在多个 Broker 上,实现水平扩展与负载均衡。
- 每个 Topic 会被划分为一个或多个 MessageQueue(消息队列),它是消息在 Broker 上的最小分片单位,也是生产者发送和消费者消费的最小操作单元。
1.5 MessageQueue
Topic: ORDER_TOPIC
├── MessageQueue 0 → Broker-A
├── MessageQueue 1 → Broker-B
└── MessageQueue 2 → Broker-C🎯关键特性
- 具有 FIFO(先进先出) 的特性,保证队列内消息的有序性。
- 每个 MessageQueue 存储在某个具体的 Broker 上。
- 生产者发送消息时,从 Topic 的多个 MessageQueue 中选择一个进行写入。
- 消费者消费时,订阅的是 Topic,但实际是从其下的多个 MessageQueue 拉取消息。
1.6 tags
Topic是一级分类,它定义了消息的高层次分类或业务领域。而Tag则是在Topic的基础上,对消息进行更细粒度的分类,可以理解为二级分类。
在发送消息时,生产者需要指定消息所属的Topic和Tag(如果有的话)。在消费消息时,消费者也需要指定要订阅的Topic,并可以选择性地指定要接收的Tag(或使用通配符来接收所有Tag的消息)。
Tag 过滤发生在 Broker 端,称为 “服务器端过滤”。Broker 会根据消费者的订阅表达式,只将匹配的消息推送给该消费者,减少网络传输和客户端压力。
生产者发送:
Topic: ORDER_TOPIC
Tag: PAID
↓
Broker 存储
消费者订阅:
subscribe("ORDER_TOPIC", "PAID || CANCEL")
↓
Broker 匹配:
- PAID → 匹配 ✅ → 推送
- CANCEL → 匹配 ✅ → 推送
- CREATE → 不匹配 ❌ → 丢弃(不推送)1.7 Broker
Broker 是 RocketMQ 架构中的核心服务节点,承担消息的接收、存储、转发与查询等关键职责,是整个消息系统性能与可靠性的基石。在部署中,每个 Broker 对应一台独立的服务器(物理机或虚拟机)。
🎯消息中转与持久化存储
- 接收来自 Producer 的消息写入请求。
- 将消息持久化存储到本地磁盘(基于内存映射 mmap + 顺序写优化),确保高吞吐与高可靠性。
- 为 Consumer 的拉取请求准备数据,支持高效的消息读取。
🎯客户端请求处理中枢
统一处理所有来自客户端(Producer 和 Consumer)的请求,包括:
- 消息发送(Send)
- 消息拉取(Pull)
- 心跳上报
- 订阅关系管理
- 消费进度(Offset)提交与查询
🎯元数据管理
维护与消息相关的各类元数据,包括:
- Topic 与 MessageQueue 的映射关系
- 消费者组(Consumer Group)的订阅信息(如订阅了哪些 Topic)
- 各消费者组在每个 MessageQueue 上的消费进度偏移量(Consumer Offset)
- 延迟消息的调度信息
- 消息索引数据
🎯消息索引服务
- 根据消息的 唯一 Key(如订单 ID)建立哈希索引。
- 提供基于 Message Key 的快速查询能力(queryMsgByUniqueKey),便于问题排查与消息追溯。
- 索引文件独立存储,不影响主消息文件的写入性能。
1.8 MessageKey
- 唯一标识与查询:
- Message Key在业务层面通常被用作消息的唯一标识。这意味着,一旦为消息设置了Key,就可以根据这个Key来查找或追踪消息。
- RocketMQ会为每个设置了Key的消息创建专门的索引文件,这些文件存储了Key与消息的映射关系。由于采用了哈希索引,因此应尽量确保Key的唯一性,以避免潜在的哈希冲突。
- 消息去重与幂等性:
- 在某些业务场景中,需要确保消息的唯一性和幂等性。通过设置唯一的Message Key,消费者可以在处理消息时检查该Key是否已经被处理过,从而实现消息的去重和幂等性保证。
- 消息过滤:
- 虽然Message Key本身并不直接用于消息过滤,但它可以作为消息的一个属性,与Tag等其他属性一起,在消费者端实现更复杂的消息过滤逻辑。
- 方便的问题排查:
- 当消息处理过程中出现问题(如消息丢失、异常等)时,Message Key可以作为快速定位问题的手段。通过查询或追踪具有特定Key的消息,可以迅速发现问题的根源。
- 提升查询效率:
- RocketMQ为设置了Key的消息创建了专门的索引文件,这些索引文件可以加速查询过程。
1.9 NameServer 轻量级路由发现中心
🎯概念
NameServer 是 RocketMQ 架构中的轻量级服务发现与路由管理组件,它不参与消息的收发与存储,而是专注于:
- ✅ 维护 Broker 的路由信息
- ✅ 为 Producer 和 Consumer 提供 Broker 地址发现服务
高可用与集群设计(三大核心特性):
- 可横向扩展:NameServer可以集群部署,当需要增加系统的处理能力时,可以通过增加NameServer的节点数量来横向扩展集群。
- 无状态:NameServer集群中的每个节点都是无状态的,所有路由信息都来自 Broker 的主动上报,节点重启后,只要 Broker 重新注册,路由信息即可恢复。
- 节点之间互不通信:NameServer 集群中的各个节点彼此独立、互不通信,也不做数据同步。路由信息的“最终一致性”是通过 Broker 向所有 NameServer 节点并行上报心跳 来实现的。
工作流程图解:
Broker 启动
↓
向所有 NameServer 节点发送心跳(包含自身信息 + Topic 路由)(发送的是全量的消息)(每隔30秒发送一次)
↓
NameServer1、NameServer2、NameServer3 分别存储路由信息(彼此不通信)
Producer/Consumer 启动
↓
从配置的 NameServer 列表中随机选择一个(如 NameServer2)
↓
拉取 Topic 的路由信息(包含哪些 Broker 可用)
↓
直接连接对应的 Broker 发送或消费消息
Broker 宕机
↓
停止向 NameServer 发送心跳
↓
NameServer 检测到心跳超时(默认 120s)→ 从路由表中移除该 Broker🎯核心职责
- Broker 注册:每个 Broker 启动后,会向所有 NameServer 节点发送心跳,注册自身信息(IP、端口、支持的 Topic、队列数等)
- 路由信息维护:NameServer 存储并维护每个 Topic 的路由表:包含哪些 Broker、每个 Broker 上有哪些 MessageQueue
- 路由查询服务:Producer 和 Consumer 在启动时,从 NameServer 拉取 Topic 的最新路由信息,从而知道该连接哪些 Broker
- 心跳检测与过期清理:如果某个 Broker 连续多个周期未上报心跳(默认 120 秒),NameServer 会将其从路由表中移除,实现故障感知
🎯CAP
RocketMQ 的 NameServer 集群是 AP 模型。
✅ (1) 无状态 + 节点独立
- 每个 NameServer 节点都是独立运行、互不依赖的。
- 不像 ZooKeeper 那样有 Leader/Follower 角色,也不通过 ZAB 或 Raft 协议进行数据同步。
- 因此,没有“写多数成功才提交”的一致性机制,自然无法保证强一致性。
✅ (2) “最终一致性”替代“强一致性”
- Broker 向所有 NameServer 节点并行发送心跳。
- 所有节点在 一个心跳周期内(默认 30 秒) 会趋于一致。
- 允许短暂不一致(如某个节点刚重启),但系统整体可用。
✅ (3) 客户端容错机制保障可用性
- Producer/Consumer 配置的是 NameServer 地址列表(如 ns1:9876;ns2:9876;ns3:9876)。
- 客户端会随机选择一个节点发起路由查询。
- 如果某个 NameServer 不可用或返回空路由,客户端会自动重试其他节点,确保最终能获取到路由信息。
🎯路由注册
在 RocketMQ 架构中,路由信息的注册与维护是通过 Broker 主动向 NameServer 发送心跳(Heartbeat)实现的。这是一种“客户端驱动、服务端无状态、最终一致”的轻量级服务发现机制。
路由注册的核心机制:心跳驱动
- 发起方:Broker(主动方)
- 接收方:NameServer(被动方)
- 方式:定时心跳包(包含全量路由信息)
- 频率:默认每 30 秒 发送一次
- 目标:向 NameServer 集群中每一个节点 广播注册
全量路由信息包
- Broker 自身元数据(BrokerName、BrokerId、IP、端口、读写权限)
- 当前 Broker 承载的 所有 Topic 配置(TopicConfigTable)
- Topic 名称
- 读队列数(readQueueNums)
- 写队列数(writeQueueNums)
- 权限控制(perm)
NameServer 处理注册请求
- 更新或创建 Broker 元数据表(brokerAddrTable):
- 存储 Broker 的地址、ID、名称等基本信息。
- 更新 Topic 路由表(topicQueueTable):
- 将该 Broker 的 MessageQueue 信息注册到对应 Topic 下。
- 例如:ORDER_TOPIC 新增 4 个 MessageQueue,归属于 broker-a。
- 记录心跳时间戳:
- lastUpdateTimestamp:最后一次心跳时间(关键!)
- elapsedInterval:心跳间隔监控
定时心跳,持续续约
- Broker 启动后,启动一个定时任务(默认每 30 秒执行一次)
- 每次执行时,重新向所有 NameServer 节点发送全量心跳包。
- NameServer 收到后,更新 lastUpdateTimestamp,表示该 Broker 仍在线。
NameServer 定时扫描,剔除失效 Broker
- NameServer 启动一个扫描任务(默认每 10 秒执行一次)
- 如果发现Broker记录的最后一次心跳时间和当前时间差超过120秒,将Broker节点信息和其承载的消息队列信息剔除。
🎯路由发现
初始化时随机选择 NameServer
- 客户端(Producer/Consumer)启动时,会配置一个 NameServer 地址列表(如ns1:9876;ns2:9876;ns3:9876)。
- 客户端在首次拉取路由时,使用轮询(Round-Robin)策略随机选择一个 NameServer 节点进行通信。
- 一旦选定,该客户端会“粘性”地优先使用该 NameServer,直到其不可用。
向 NameServer 拉取 Topic 路由信息
客户端向选定的 NameServer 发送 GET_ROUTEINFO_BY_TOPIC 请求,查询指定 Topic 的路由。
NameServer 收到请求后,返回以下关键信息:
{
"brokerAddrTable": {
"broker-a": "192.168.1.10:10911",
"broker-b": "192.168.1.11:10911"
},
"topicQueueTable": {
"ORDER_TOPIC": [
{ "brokerName": "broker-a", "queueId": 0, "readQueueNums": 4, "writeQueueNums": 4 },
{ "brokerName": "broker-a", "queueId": 1, "readQueueNums": 4, "writeQueueNums": 4 },
{ "brokerName": "broker-b", "queueId": 0, "readQueueNums": 4, "writeQueueNums": 4 }
]
},
"filterServerTable": { }
}客户端缓存路由信息
- 客户端收到路由信息后,将其缓存在本地内存(如 TopicRouteData 对象)。
- 缓存内容用于:
- Producer:选择 MessageQueue 发送消息
- Consumer:确定订阅的 MessageQueue 列表,参与 Rebalance
定时任务刷新路由缓存
- 客户端启动一个定时任务(默认每 30 秒 执行一次)
- 向当前优先的 NameServer 发起路由查询
- 比较新旧路由信息
- 如果有变更(新增 Broker、队列数变化、Broker 下线),触发
- Producer:更新可发送队列列表
- Consumer:触发 Rebalance(重新分配 MessageQueue)
- 如果有变更(新增 Broker、队列数变化、Broker 下线),触发
- 更新本地缓存。
客户端如何选择 Broker 进行通信
- Producer 发送消息时,目标是某个 Topic 的 MessageQueue,而不是 Broker。使用负载均衡策略(如 MessageQueueSelector)选择一个 MessageQueue。从缓存中查出该 Queue 所属的 Broker 地址,建立连接并发送。
- Consumer 订阅 Topic 后,通过 Rebalance 分配到若干个 MessageQueue。每个 Queue 对应一个 Broker。Consumer 会同时与多个 Broker 建立长连接,并行拉取消息。如果某个 Broker 宕机,Rebalance 会将其 Queue 重新分配给其他 Consumer。
🎯为何不使用Zookeeper
- 服务发现系统应当以高可用为首要目标,确保在任何节点故障或网络波动的情况下,客户端仍能持续获取路由信息。
- ZooKeeper 的持久化对路由场景不必要,ZooKeeper 使用 ZAB 协议,每个写请求都需记录事务日志 + 内存快照,以保证强一致与持久化。但对于 RocketMQ 的路由发现场景,路由信息由 Broker 心跳上报,可实时重建,无需强持久化。
- 扩展性差:ZooKeeper 写不可扩展,NameServer 更易横向扩展。ZooKeeper 的写操作由 Leader 串行处理,无法水平扩展写性能。要提升容量只能部署多个集群,导致运维复杂,且形成孤岛,违背高可用初衷。
1.10 配置参数
🎯brokerClusterName
- 通过为不同的Broker集群设置不同的brokerClusterName,可以清晰地标识和区分它们。这有助于管理员和用户识别、管理和监控不同的Broker集群。
- 当Broker集群中的某个节点出现故障时,RocketMQ可以根据集群名称来识别该节点所属的集群,并执行相应的故障恢复策略。此外,brokerClusterName还可以帮助实现负载均衡,使得Producer和Consumer能够均匀地将消息发送到或拉取自不同的Broker节点。
- 在RocketMQ的分布式服务架构中,NameServer负责服务注册与发现。Broker节点会将自己的信息注册到NameServer中,而NameServer则负责为Producer和Consumer提供路由信息。brokerClusterName是这些注册信息中的一个重要字段,它允许NameServer根据集群名称来识别和管理Broker节点。
🎯brokerRole
用于定义 Broker 在集群中的角色和行为。这个参数决定了 Broker 是作为主节点(Master)、从节点(Slave),还是同时承担两者职责的双写模式(异步或同步)。
brokerRole=SYNC_MASTER,Broker 作为主节点运行,同步双写,就是master和slave都要写成功之后,才反馈给客户端写成功的状态。brokerRole=ASYNC_MASTER,Broker 作为主节点运行,异步复制,只要master写成功了,就可以反馈给客户端写成功状态。brokerRole=SLAVE,从节点仅作为备份存在,不能直接接收生产者的消息。
🎯flushDiskType
flushDiskType=ASYNC_FLUSH,异步刷盘方式,当设置为 ASYNC_FLUSH 时,Broker 接收到消息后,首先将消息写入内存缓冲区,然后立即返回成功响应给生产者。后台线程会定期将内存中的消息批量写入磁盘。这种方式提供了较高的吞吐量和较低的延迟,但可能会面临一定的数据丢失风险。flushDiskType=SYNC_FLUSH,同步刷盘方式,Broker 在接收到生产者的消息后,会立即将消息写入磁盘,并等待写操作成功确认后再返回成功响应给生产者。这种方式确保了消息的持久化,即使系统突然宕机,也不会导致消息的丢失。但同步刷盘相对于异步刷盘来说,会有更高的延迟和更低的吞吐量。
🎯retryAnotherBrokerWhenNotStoreOK
- 当 retryAnotherBrokerWhenNotStoreOK 设置为 true 时,如果消息在发送到某个 broker 时由于存储问题而失败(例如,消息写入磁盘超时或 slave broker 不可用),RocketMQ 客户端会尝试将消息重新发送到其他可用的 broker。
- 当 retryAnotherBrokerWhenNotStoreOK 设置为 false 时,RocketMQ 客户端不会尝试重新发送消息到其他 broker,而是直接返回发送失败的结果。
- 默认值为false。
🎯waitStoreMsgOK
- 该参数用于指定在发送消息时是否等待消息在Broker端存储完成后再返回应答。
- 当设置为true时,生产者会等待Broker确认消息已经成功存储到磁盘或持久化存储中,然后返回发送结果。
- 当设置为false时,生产者发送消息后会立即返回,不会等待Broker端的存储确认。
- 默认情况下,waitStoreMsgOK的值为true
- waitStoreMsgOK关注的是生产者发送消息后是否等待Broker的存储确认,影响的是消息的发送可靠性和延迟。
- flushDiskType关注的是Broker如何将消息写入磁盘,影响的是消息的持久化可靠性和写入性能。